Protein Folds & Domains
Protein secondary structure elements, such as helices, strands, and loops, connect and arrange to form a protein’s three-dimensional structure. From known experimental protein structures, we have learned that only a limited number of combinations and connectivities can link these secondary structure elements into domains in nature. These combinations are often unique to specific protein families and are referred to as a fold (or topology, at the CATH database). The analysis in this section will explore examples of how secondary structure elements connect and pack within protein domains. A domain is the basic unit of classification for proteins, and its analysis simplifies the comparison of protein structures, highlighting similarities and differences while paving the way for studying sequence-structure-function relationships.
Protein Domain Definition
A domain may be characterized by the following:
- Spatially separated folding unit of the protein structure
- Often has sequence and/or structural resemblance to other protein structures or domains.
- Often, it has a specific, evolutionary conserved function associated with it.
- A domain is the basic fold classification unit
Some proteins consist of a single domain; examples include triose phosphate isomerase (TIM), plastocyanin, and hemoglobin. However, many proteins contain multiple domains and are referred to as multidomain proteins. I will first provide examples of one-domain proteins and their structures, followed by a discussion on multidomain proteins and multi-subunit (oligomeric) complexes. Authors in biochemical literature often use the term “domain” to refer to a subunit in an oligomeric complex of multiple proteins (multi-subunit complex). This usage can be misleading since a subunit is a separate polypeptide, and its three-dimensional structure may consist of one or several domains. Here, we will adhere to the definition of a domain as a fundamental fold classification unit.
The Helix Bundle Domain
One of the most common structural domains in proteins is the helix bundle domain. The images below illustrate three different helix bundles. On the left is a stand-alone 4-helix bundle of a de novo-designed protein (PDB ID 1MFT); in the middle is the X-ray structure of human O6-alkylguanine-DNA alkyltransferase, which possesses two domains, an α-β domain, and a helix bundle domain (PDB ID 1QNT). On the right is the structure of the human hormone progesterone receptor complexed with its ligand (PDB ID 1A28). In a helix bundle domain, the helices are interconnected by loop regions (either short or long) and often create a hydrophobic core at the center of the bundle. The examples in the figures demonstrate that the loops are relatively short in the left image but significantly longer in the middle image and of mixed length in the right. The images are linked to their respective pages on the PDB.



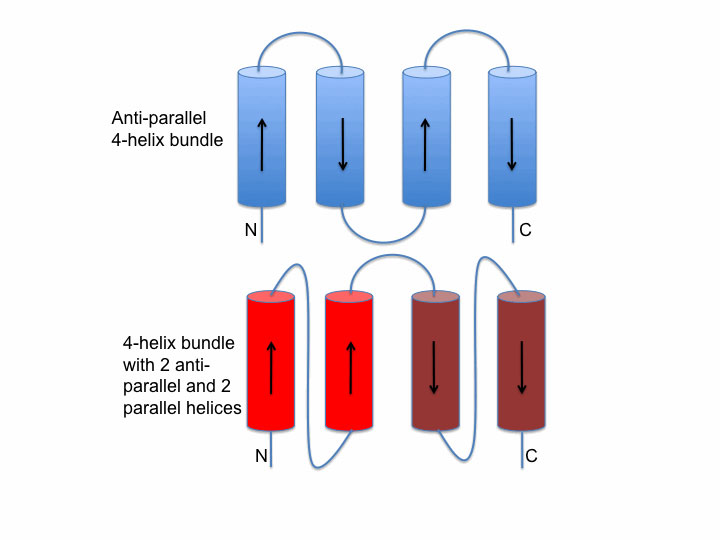
Helix bundle packing
The image on the left shows two schematic examples of connectivity between helices in a bundle. The upper packing (blue) shows an antiparallel bundle. The red bundle shows an example where two helices are parallel to each other and antiparallel to the second pair.
The Rossmann Fold Domain
An example of the strand-loop-helix motif is provided by the Rossmann fold domain, named after Michael G. Rossmann, a protein crystallographer who solved the structure of lactate dehydrogenase (LDH) in which this domain was identified. The Rossmann fold is the only protein fold named after the person who discovered it. This domain type is widespread and can be found in many multidomain proteins involved in binding nucleotide cofactors like NADH, FAD, FMN, as well as ATP and GTP. An excellent discussion of details and the history of the Rossmann fold can be found on Proteopedia.
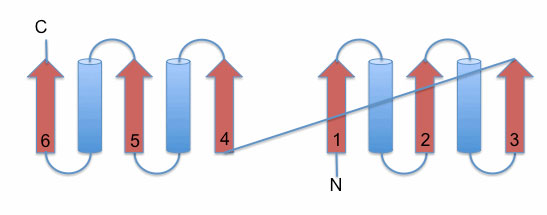
The left image below illustrates a schematic representation of the Rossmann fold. It consists of a parallel 6-stranded β-sheet flanked by α-helices. The right image displays the 6-stranded parallel Rossmann fold β-sheet of the enzyme liver alcohol dehydrogenase (LDH). The NADH molecule bound at the top of the β-sheet is shown as a stick model (PDB 2OHX). The parallel β-sheet is flanked by α-helices on both sides of its plane. For clarity, the two helices positioned on top of the sheet are omitted from the image.
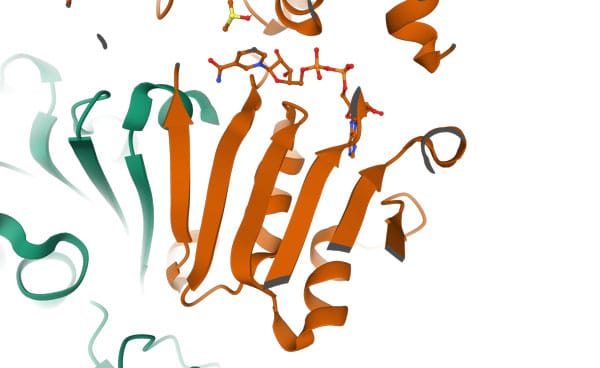
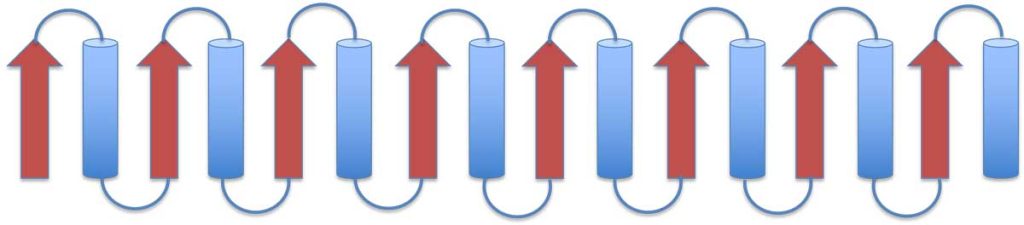
The TIM barrel domain
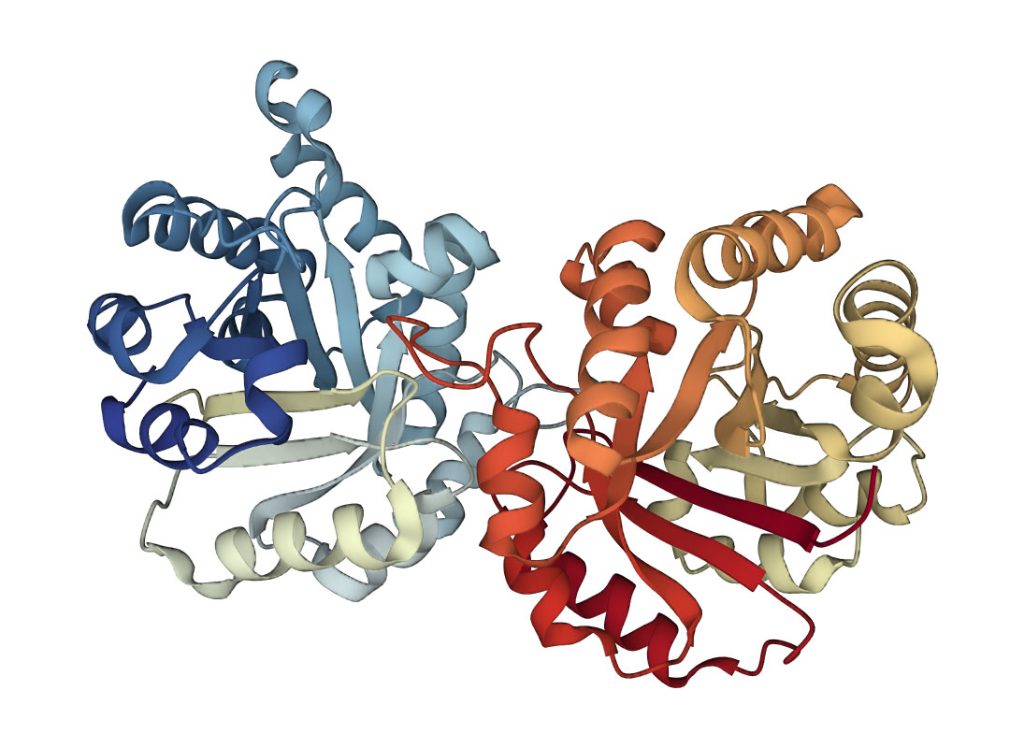
Triose phosphate Isomerase (TIM) is a single-domain protein and the first representative of the TIM barrel fold. This fold is widespread and can be found in many proteins. In this structure, the strands of the β-sheet are parallel and linked by loops and helices. Details of the mechanism and function of this protein can be found on Proteopedia. On the left image is a schematic presentation of the fold, while on the right is a ribbon presentation of the three-dimensional structure of triose phosphate isomerase dimer. Clicking on the image will take you to the PDB page.
These are just some examples of protein domains and folds. On the next page, I will continue this theme and discuss the fold classification database CATH.
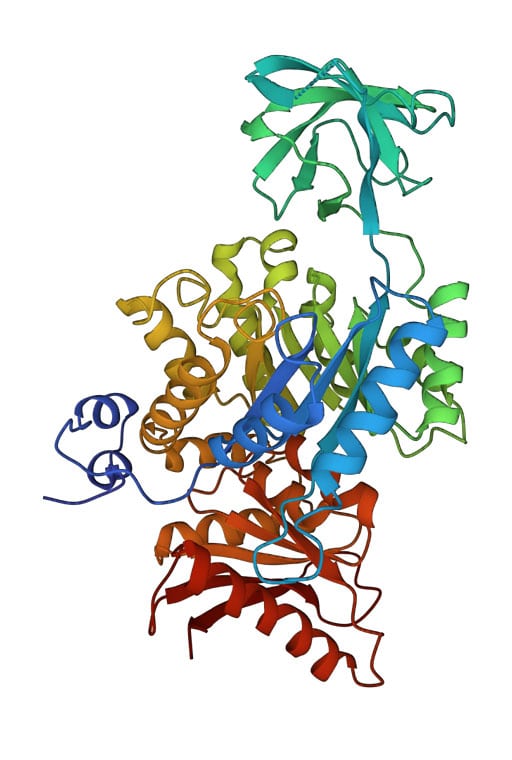
Multidomain Proteins: Pyruvate Kinase
As mentioned earlier, while some proteins contain a single domain, others may contain two or more domains. Below is an example of a 3-domain pyruvate kinase (PDB ID 1PKN). The domains are well-separated and exhibit different folds. For example, the top domain in the image is a β-sheet domain, while the other two are of the alpha/beta type (see the respective Proteopedia page for details about this enzyme). In most organisms, the functional unit of pyruvate kinase is a tetramer (comprising four subunits), resulting in a total of 12 domains.